PostgreSQL Locks
A Practical Guide to Boosting Performance and Managing Concurrent Processes
In today’s digital era, managing large datasets has become a critical aspect of many businesses.
This has led to the adoption of relational database management systems (RDBMS), such as PostgreSQL, which provide robust mechanisms for efficient and reliable data management.
One essential component of any RDBMS is locking, which helps manage concurrent access to data by multiple users or processes.
PostgreSQL provides various types of locks that allow for concurrent transactions while ensuring data consistency and integrity. Improper locking can result in performance degradation and data inconsistency, leading to significant issues for any business.
In this tutorial, we will dive into the theory and show practical examples. We will explore different types of locks and common lock modes available in PostgreSQL, their functions, and various strategies for optimizing locking performance.
By the end of this post, you will have a clear understanding of how locks contribute to PostgreSQL performance and how to implement effective locking strategies for optimal database performance and data management.
You’ll also get to know the lock explorer feature in Datasentinel which facilitates monitoring locks in PostgreSQL in real time.
Interactive Demo: Experience PostgreSQL Locks in Action
Before we dive deep into the intricacies of PostgreSQL locks, we invite you to explore our interactive demo.
This hands-on experience is designed to give you a tangible understanding of how locks impact database performance and behavior in real-time scenarios.
This demo will provide you with a practical framework to better appreciate the concepts and solutions discussed throughout this post.
Understanding PostgreSQL Locks
PostgreSQL provides various types of locks to ensure data consistency and prevent conflicts when multiple transactions access the same data simultaneously.
In this tutorial, we will discuss the most common lock modes of PostgreSQL that exist in the following lock types; table-level locks, row-level locks, page-level locks, deadlocks, and advisory locks.
But first, we need to know the difference between lock types (an example is a table-level lock) and lock modes (an example is an Access Share lock).
In PostgreSQL, the lock modes can be categorized for example as table-level and row-level locks based on the scope of the lock. However, the names of the lock modes do not necessarily reflect the scope of the lock. The name “ACCESS SHARE” implies that it’s a table-level lock, but it can also be used as a row-level lock in certain cases.
Similarly, row-level lock modes like ROW SHARE, ROW EXCLUSIVE, and SHARE UPDATE can also be used as table-level locks in certain cases. So, it’s important to understand the context in which a lock mode is used and how it interacts with other lock modes to ensure data consistency and avoid deadlocks.
The following table that exists on the PostgreSQL Explicit Locking documentation page explains the different types of conflicting lock modes:
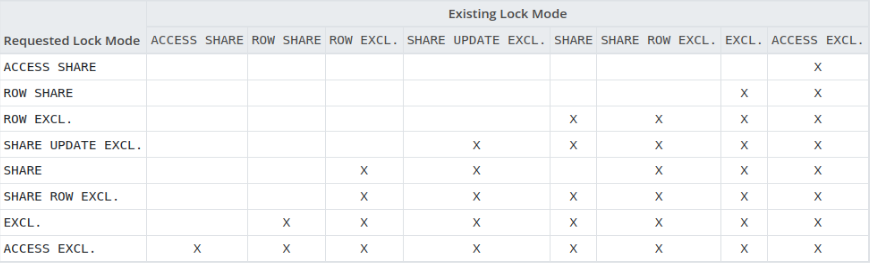
Conflicting Lock Modes – Image from PostgreSQL documentation
The table shows which lock modes can be acquired with the presence of other lock modes, which is crucial for understanding how Lock modes interact with each other and for choosing the appropriate lock mode for a given scenario.
To have a better understanding of how Lock modes conflict with each other, you need to revise this table as we explain the most common lock modes in the following sub-sections.
Access Share (AccessShareLock)
This lock allows concurrent read-only access to a table. Multiple transactions can hold an AccessShareLock on the same object simultaneously.
In general, any query that reads data from a table but does not modify it will acquire an ACCESS SHARE lock.
This includes SELECT queries, as well as queries that perform operations like COUNT, MIN, MAX, and AVG.
It’s worth noting that an ACCESS SHARE lock does not prevent other transactions from acquiring shared locks on the same table, so multiple transactions can hold ACCESS SHARE locks on a table at the same time. However, if a transaction attempts to acquire an ACCESS EXCLUSIVE lock while another transaction holds an ACCESS SHARE lock, it will be blocked until the ACCESS SHARE lock is released.
Below is a simple example that demonstrates the ACCESS SHARE lock mode in PostgreSQL.
You have set up the unix_db database and you open up a new psql session to retrieve a certain row from the users table:
unix_db=# -- session 1
unix_db=# \x -- activate the expanded window
Expanded display is on.
unix_db=# BEGIN; -- begin a transaction
BEGIN
unix_db=# SELECT displayname FROM users WHERE id = 14;
-[ RECORD 1 ]--
displayname | BThis SELECT statement has made PostgreSQL acquire an ACCESS SHARE lock.
To make sure we’re correct, let’s run the following query from the pg_locks system view:
unix_db=# SELECT * FROM pg_locks WHERE relation::regclass::text = 'users'::text;
-[ RECORD 1 ]------+----------------
locktype | relation
database | 195035
relation | 195046
page |
tuple |
virtualxid |
transactionid |
classid |
objid |
objsubid |
virtualtransaction | 4/65
pid | 50128
mode | AccessShareLock
granted | t
fastpath | tThis query retrieves all the locks in the users table. So far, there is only one lock (AccessShareLock) in the session with the pid number (50128).
Let’s make sure that the current session (session 1) really has this pid with the following command:
unix_db=# SELECT pg_backend_pid();
-[ RECORD 1 ]--+------
pg_backend_pid | 50128That confirms that we have an access share lock on session 1.
Keep this transaction running and open a new transaction and enter the following commands:
unix_db=# -- session 2
unix_db=# \x
Expanded display is on.
unix_db=# BEGIN;
BEGIN
unix_db=# SELECT displayname FROM users WHERE id = 13;
-[ RECORD 1 ]--
displayname | FAs you can see, two sessions can do read operations on the same table. That’s because an access share lock doesn’t conflict with another access share lock as you can see from the pg_locks system catalog:
unix_db=# SELECT * FROM pg_locks WHERE relation::regclass::text = 'users'::text;
-[ RECORD 1 ]------+----------------
locktype | relation
database | 195035
relation | 195046
page |
tuple |
virtualxid |
transactionid |
classid |
objid |
objsubid |
virtualtransaction | 4/65
pid | 50128
mode | AccessShareLock
granted | t
fastpath | t
-[ RECORD 2 ]------+-----------------
locktype | relation
database | 195035
relation | 195046
page |
tuple |
virtualxid |
transactionid |
classid |
objid |
objsubid |
virtualtransaction | 4/9
pid | 10958
mode | AccessShareLock
granted | t
fastpath | tSo we have AccessShareLock on both session 1 and session 2.
An Access Share Lock can not also conflict with a Row Access Exclusive Lock. Let’s take a look at the following query on session 2:
unix_db=# UPDATE users SET displayname = 'Bryan' WHERE id = 14;
UPDATE 1So the update statement is accepted and the pg_locks is now added with the following RowExclusiveLock type:
-[ RECORD 3 ]------+-----------------
locktype | relation
database | 195035
relation | 195046
page |
tuple |
virtualxid |
transactionid |
classid |
objid |
objsubid |
virtualtransaction | 5/2
pid | 10930
mode | RowExclusiveLock
granted | t
fastpath | tIn fact, the Access Share Lock only conflicts with the Exclusive Lock. Let’s take a look at the following query on session 2:
unix_db=# DROP TABLE users;Running this DROP statement will make the session freeze because its type of lock conflicts with existing locks.
Let’s make sure of the new type of lock introduced here. If you run the query on pg_locks on session 1, you’ll see an updated record that looks like the following:
-[ RECORD 4 ]------+--------------------
locktype | relation
database | 195035
relation | 195046
page |
tuple |
virtualxid |
transactionid |
classid |
objid |
objsubid |
virtualtransaction | 5/2
pid | 10930
mode | AccessExclusiveLock
granted | f
fastpath | fThis is the new lock we currently have on session 2 that conflicted with the existing Access Share and Row Exclusive locks.
So to make sure to abort that transaction, click on Ctrl+C on your keyboard:
unix_db=# DROP TABLE users;
^CCancel request sent
ERROR: canceling statement due to user requestIf you do a SELECT statement from this table, you’ll see the following error:
unix_db=# SELECT displayname FROM users WHERE id = 14;
ERROR: current transaction is aborted, commands ignored until end of transaction blockThis error message indicates that a transaction has been aborted due to an error, and any further commands issued in that transaction will be ignored until the transaction is ended or rolled back.
In PostgreSQL, a transaction is a set of SQL statements executed as a single unit of work. If an error occurs during the execution of any statement within a transaction, the entire transaction will be aborted and rolled back to its previous state. This ensures data consistency and integrity.
So if we rollback, we will have the same data as we had on session 2 before beginning the transaction:
unix_db=# ROLLBACK;
ROLLBACK
unix_db=# SELECT displayname FROM users WHERE id = 14;
-[ RECORD 1 ]--
displayname | BFinally, let’s end the first transaction with END or COMMIT.
Row Share (RowShareLock)
ROW SHARE lock mode is acquired by the SELECT command when any of the following options are specified: FOR UPDATE, FOR NO KEY UPDATE, FOR SHARE, or FOR KEY SHARE.
The ROW SHARE lock mode allows multiple transactions to read the same row simultaneously, but it conflicts with the EXCLUSIVE and ACCESS EXCLUSIVE lock modes.
Here’s an example of how ROW SHARE lock mode works with two concurrent transactions:
- The first transaction executes a SELECT statement with FOR SHARE option on the users table, filtering on the row with id = 14.
- The second transaction executes an UPDATE statement on the same row (id = 14) of users table.
The first transaction:
unix_db=# -- session 1
unix_db=# BEGIN;
BEGIN
unix_db=# SELECT displayname FROM users WHERE id = 14 FOR SHARE;
-[ RECORD 1 ]--
displayname | BIf you try to execute the second transaction (in another psql session) while the first transaction is still running, you’ll see it being blocked:
unix_db=# -- session 2
unix_db=# BEGIN;
BEGIN
unix_db=# UPDATE users SET displayname = 'Bryan' WHERE id = 14;Since the first transaction has acquired a Row Share lock on the row with id = 14, the second transaction (that acquired the Exclusive lock) will be blocked until the lock is released.
Let’s make sure that the previous update statement had an Exclusive lock. Enter the following command on the first session:
unix_db=# SELECT pid, mode FROM pg_locks WHERE relation::regclass::text = 'users'::text;
-[ RECORD 1 ]----------
pid | 10930
mode | RowExclusiveLock
-[ RECORD 2 ]----------
pid | 10958
mode | RowShareLock
-[ RECORD 3 ]----------
pid | 10930
mode | ExclusiveLockSo the blocked session (that has the second transaction, with the process id 10930) has two lock modes; one of them is Exclusive lock which blocked the session.
Share Update Exclusive (ShareUpdateExclusiveLock)
The SHARE UPDATE EXCLUSIVE lock mode in PostgreSQL protects a table against concurrent schema changes and vacuum runs.
This lock mode is acquired by various PostgreSQL commands like VACUUM (without FULL), ANALYZE, CREATE INDEX CONCURRENTLY, CREATE STATISTICS, COMMENT ON, REINDEX CONCURRENTLY, and certain ALTER INDEX and ALTER TABLE variants.
Let’s see that in action in the following example.
Open a session and enter an ANALYZE command:
unix_db=# -- session 1
unix_db=# BEGIN;
BEGIN
unix_db=# ANALYZE users;
ANALYZEThe ANALYZE command in PostgreSQL is used to collect statistics about the contents of a table. These statistics are then used by the query planner to optimize queries for the table.
Leave that session running the transaction and open a second session:
unix_db=#
unix_db=# -- session 2
unix_db=# BEGIN;
BEGIN
unix_db=# ANALYZE users;
-- blocked by the first sessionTo make sure what’s currently blocking this session:
unix_db=# SELECT pid, mode FROM pg_locks WHERE relation::regclass::text = 'users'::text;
-[ RECORD 1 ]------------------
pid | 10958
mode | ShareUpdateExclusiveLock
-[ RECORD 2 ]------------------
pid | 10930
mode | ShareUpdateExclusiveLockAs you can see, another Share Update Exclusive lock was the blocking reason.
Share (ShareLock)
The SHARE lock mode protects a table against concurrent data changes. It is acquired during index creation (without the CONCURRENTLY option).
Let’s take the following example.
In the first session:
unix_db=# -- session 1
unix_db=# BEGIN;
BEGIN
unix_db=# CREATE INDEX user_reputation_idx ON public.users USING btree (reputation);
CREATE INDEX
unix_db=# And the second session:
unix_db=# -- session 2
unix_db=# BEGIN;
BEGIN
unix_db=# SELECT displayname FROM users WHERE id = 14;
-[ RECORD 1 ]------
displayname | Bryan
unix_db=# DELETE FROM users WHERE id = 14;
-- blocked by the first sessionTo check the lock modes, run the following on the first session:
unix_db=# SELECT pid, mode FROM pg_locks WHERE relation::regclass::text = 'users'::text;
-[ RECORD 1 ]----------
pid | 10958
mode | ShareLock
-[ RECORD 2 ]----------
pid | 10930
mode | RowExclusiveLockAs you can see, a Share lock is acquired in the first session (by creating the index).
This lock conflicts with the Row Exclusive lock in the second session (created by the DELETE command). The conflict will be released once we commit or roll back the session.
So you can abort the second transaction and roll back that change (if you don’t want to delete that record). Press Ctrl+C and then type ROLLBACK on the second session.
Deadlocks
When two or more transactions are waiting for one another to release locks, a deadlock occurs. PostgreSQL identifies and resolves deadlocks automatically by rolling back one of the transactions.
Here is an example of a deadlock scenario with two SQL transactions in the following sessions:
| Session 1 | Session 2 |
|---|---|
| BEGIN; | |
| BEGIN; | |
| UPDATE users SET displayname = ‘Frozen’ WHERE id = 13; | |
| UPDATE users SET displayname = ‘Bryan M.’ WHERE id = 14; | |
| UPDATE users SET displayname = ‘Bryan M.’ WHERE id = 14; | |
| UPDATE users SET displayname = ‘Frozen’ WHERE id = 13; |
As you can see in this order, you’ll notice the first freeze happens when we update the user with id = 14 to “Bryan M.”. However, the following update statement in the session 2 produces the following deadlock error:
ERROR: deadlock detected
DETAIL: Process 10930 waits for ShareLock on transaction 979866; blocked by process 10958.
Process 10958 waits for ShareLock on transaction 979867; blocked by process 10930.
HINT: See server log for query details.
CONTEXT: while updating tuple (0,25) in relation "users"This deadlock error message indicates that two processes, identified by their process IDs (PID), are deadlocked and each is blocking the other. In this specific case, process 10930 (session 2) is waiting for a ShareLock on transaction 979866 while being blocked by process 10958, which is waiting for a ShareLock on transaction 979867.
Advisory Locks
Advisory locks provide a way to create locks with application-defined meanings in PostgreSQL.
This means that the system does not mandate their use, and it is the application’s responsibility to utilize them correctly. Advisory locks have the advantage of being useful for locking schemes that do not suit the MVCC model well. For instance, they can be used to simulate the pessimistic locking mechanisms typical in “flat file” data management systems.
Unlike regular locks, advisory locks are faster, avoid table bloat, and are automatically cleaned up by the server at the end of the session. Additionally, advisory locks can be acquired at the session level or transaction level, providing more flexibility to the application developer. This allows for a wide range of locking strategies to be implemented, tailored to specific use cases.
Overall, the benefit of advisory locks is that they provide a powerful tool for application developers to implement custom locking strategies that are not easily achieved using regular locks.
Let’s take an example of pessimistic locking below. First, let’s define what pessimistic locking is.
Pessimistic locking is a strategy in which a process acquires a lock on a resource and holds onto it for the duration of a transaction, preventing other processes from accessing the resource until the transaction is committed or rolled back. This strategy is useful when there is a high likelihood of contention for a particular resource, and when it is important to ensure that only one process is modifying the resource at a time.
Let’s say we have a web application that allows users to purchase plane tickets. We want to ensure that only one user can purchase a ticket for a particular seat at a time, to avoid double bookings.
When a user selects a seat to purchase, we acquire an advisory lock on the seat ID using the pg_advisory_lock() function. Open a new session to simulate such operation:
unix_db=# -- session 1
unix_db=# BEGIN;
BEGIN
unix_db=# SELECT pg_advisory_lock(id) FROM users WHERE id = 14;
pg_advisory_lock
------------------
(1 row)To check the advisory lock type on that object id (14), let’s run the following in the same session:
unix_db=# SELECT pid, granted, mode, objid FROM pg_locks WHERE locktype = 'advisory';
-[ RECORD 1 ]----------
pid | 15759
granted | t
mode | ExclusiveLock
objid | 14So we have that advisory lock on the process id of the current session with the object that equals 14. This lock is granted to the session; the value granted is true.
Open another session and acquire an advisory lock other than 14:
unix_db=# -- session 2
unix_db=# BEGIN;
BEGIN
unix_db=# SELECT pg_advisory_lock(13);
pg_advisory_lock
------------------
(1 row)So the value is acquired successfully. If you want to acquire the same advisory lock as session 1, you’ll get blocked:
unix_db=# SELECT pg_advisory_lock(14);To check what advisory locks are currently available, let’s run the following query on session 1:
unix_db=# SELECT pid, granted, mode, objid FROM pg_locks WHERE locktype = 'advisory';
-[ RECORD 1 ]----------
pid | 15779
granted | t
mode | ExclusiveLock
objid | 13
-[ RECORD 2 ]----------
pid | 15759
granted | t
mode | ExclusiveLock
objid | 14
-[ RECORD 3 ]----------
pid | 15779
granted | f
mode | ExclusiveLock
objid | 14As you can see, 3 advisory locks are acquired. A granted one in the first session (with pid of 15759). However, session 2 has one granted advisory lock and another one not granted (with the objid of 14 which was blocked by session 1).
This would be helpful if we want to design a booking application. We would check whether the seat is still available for purchase. If the seat is already sold, we release the advisory lock and inform the user that the seat is no longer available. If the seat is still available, we proceed with the purchase.
To release the advisory lock, use the pg_advisory_unlock() function in the associated session:
SELECT pg_advisory_unlock(14);
SELECT pg_advisory_unlock(13);Strategies for Effective Locking in PostgreSQL
To optimize PostgreSQL performance and ensure data consistency, it’s crucial to implement effective locking strategies. Here are some strategies for optimizing locking in PostgreSQL:
- Use Appropriate Locking Granularity: PostgreSQL locks are implemented on a per-row level, which allows for greater concurrency. However, it’s essential to choose the appropriate locking granularity for your application to avoid excessive locking, which can impact performance.
- Use the Right Type of Lock: Using the right type of lock for a particular scenario is crucial for optimal performance. For example, using a shared lock instead of an exclusive lock can improve concurrency and performance.
- Keep Transactions Short: Long-running transactions can hold locks for extended periods, leading to contention and decreased concurrency. Keeping transactions short can reduce the likelihood of lock contention and improve concurrency.
- Tune PostgreSQL Parameters: Tuning PostgreSQL parameters can significantly impact locking performance. For example, adjusting the max_locks_per_transaction and log_lock_waits parameters can improve concurrency and reduce contention.
- Avoid Deadlocks: As we discussed, deadlocks occur when two or more transactions are waiting for each other to release locks. Proper application design and transaction management can help avoid deadlocks.
- Monitor Locking Performance: Monitoring locking performance is crucial to identifying bottlenecks and improving performance. Tools like pg_stat_activity and pg_locks can help identify locking issues.
In the next section, we will discuss how Datasentinel can help monitor locking performance in PostgreSQL sessions.
Monitoring PostgreSQL Locking Performance
Consult the user guide for instructions on utilizing the Lock Explorer feature in Datasentinel.
If you head over to the Session Workload in the Datasentinel demo, you’ll find that Datasentinel provides a Locks breakdown dashboard (that appears in yellow) that shows a visual representation of the locks in the database.
To further simplify, a graphical annotation is generated and displayed on the main chart whenever a blocking situation is encountered
This dashboard provides an overview of the different types of locks and their distribution over time.
You can put a certain filter on this dashboard like the screenshot below:
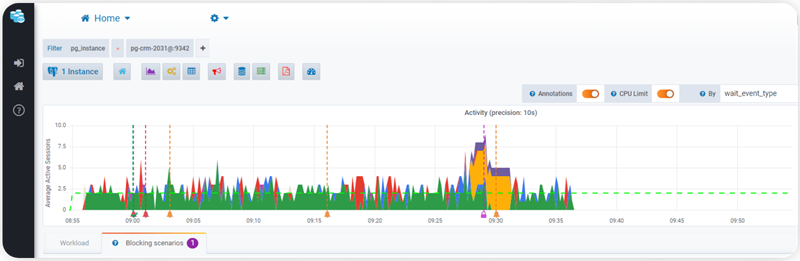
So we now have selected a certain instance of the crm database in Datasentinel demo.
If you scroll down a bit, you’ll see a Blocking Scenarios tab:
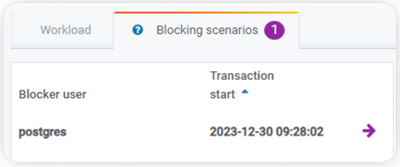
As you can see, a blocker user is shown and when that transaction started.
The blocking scenarios tab gives you insights about the different scenarios that have Locks in your database with the following attributes:

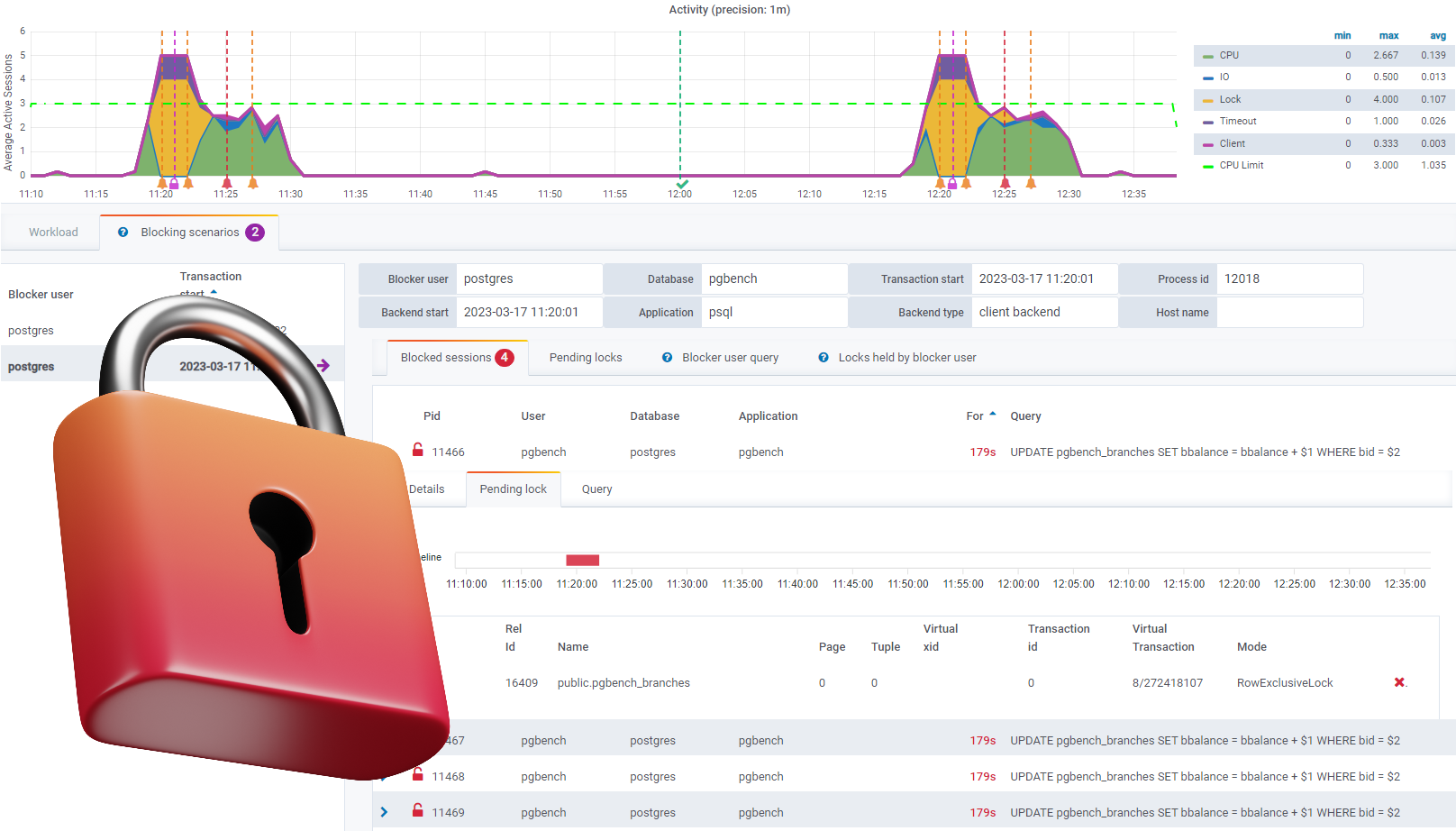
Scroll down again and you’ll see a breakdown of four tabs:
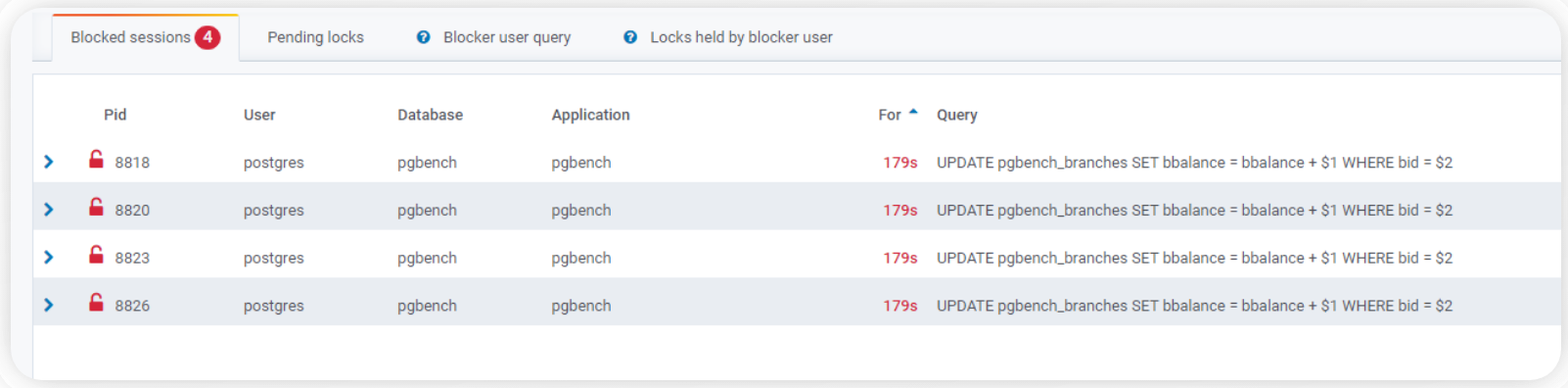
You can see above the blocked sessions with their associated process ids, users, database, application, how long it ran, and the query that acquired the lock.
You can also get a breakdown of each session by clicking on it:
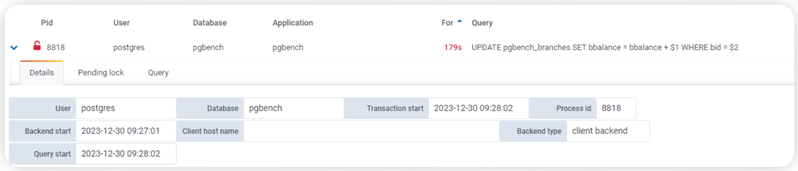
Click on the Pending locks tab and you’ll see something like the following:

This shows the lock type that is pending (e.g. relation, check the wait events of type lock table ), the relation’s id and name, the lock mode (e.g. RowExclusiveLock), and the blocked sessions (e.g. 8).
If you click on the Blocker user query tab, you’ll see the current query scanned when the blocking scenario was created:

And clicking on the Locks held by blocker user tab will give you insight about the lock that is the reason for blocking:

In this case, it’s a stronger lock than a RowExclusiveLock mode as expected which is ExclusiveLock as you can see above with the green locker emoji.
Conclusion
In conclusion, understanding the role of locking in PostgreSQL is critical for effective data management and optimal database performance. By implementing effective locking strategies and monitoring Locks in real-time, businesses can ensure data consistency, integrity, and availability.
Remember to choose the appropriate locking granularity, use the right type of lock, keep transactions short, tune PostgreSQL parameters, avoid deadlocks, and monitor locking performance.
With the help of Datasentinel’s locker explorer feature, businesses can monitor locks in PostgreSQL in real time and identify blocking scenarios, lock modes, and lock types, thereby facilitating efficient management of database locking. Armed with the knowledge and tools to optimize PostgreSQL locking, businesses can ensure reliable and efficient data management, enabling them to focus on their core business objectives.
Discover more about this key feature and others in Datasentinel by visiting our Documentation, your gateway to enhanced PostgreSQL performance.